A brief history…
xto10x started with the mission of helping startups scale. Setting the startup ecosystem on the right data science journey is an integral part of this mission. We started our discovery process engaging with several startups in an observation mode before getting into solutioning mode..
Everyone agreed that data is a super power and an essential component of scaling journey. At the same time, there were a lot of questions in everyone’s mind. When is the right time to invest in data science? What is the right way to go about it? Whom should I hire?
As we spent more time just working with startups closely, we realized that the key challenges in building an effective data science function in the startup ecosystem are not the models or the tools or the talent. It is something beyond this. Fundamental mindset and approach changes are needed to change the typical journey that all startups go through to an ideal journey. For starters the very first mindset change needed is the definition of data science itself. A simpler definition of data science like – “making data useful for business”. A definition that demystifies the complexity associated with the term and breaks silos making data science everyone’s responsibility in an organization.
Typical Journey of startups
Anyone who tries to list down 5 stages in a typical data science journey of startups would come up with these:
- We are collecting all the data we can
- We have collected a lot of data
- We need to hire data scientists
- What problems can data scientists solve given the data we have collected?
- Did it have impact?
This journey is quite natural and has happened at several successful start-ups as well. What makes this journey not-so ideal is the missed opportunity of leveraging the full potential of data science.
Based on our experience of working with a few startups , one minor tweak to each stage can fundamentally shift this journey to ideal. Here’s how it goes…
1. We are collecting all the data we can should
The very first tweak is to reach a state of confidence where a startup can say we are collecting all the data we “should”. That can happen only with clarity on what data should achieve for the business. A Data Strategy Sprint based on the “drivetrain” approach outlined in Strata conference of 2012 by Jeremy Howard is what helped us achieve that clarity and confidence with several startups [1].
Drivetrain model is an approach where we start with the business goal and with a list of subsequent questions and end up with a data strategy blueprint.
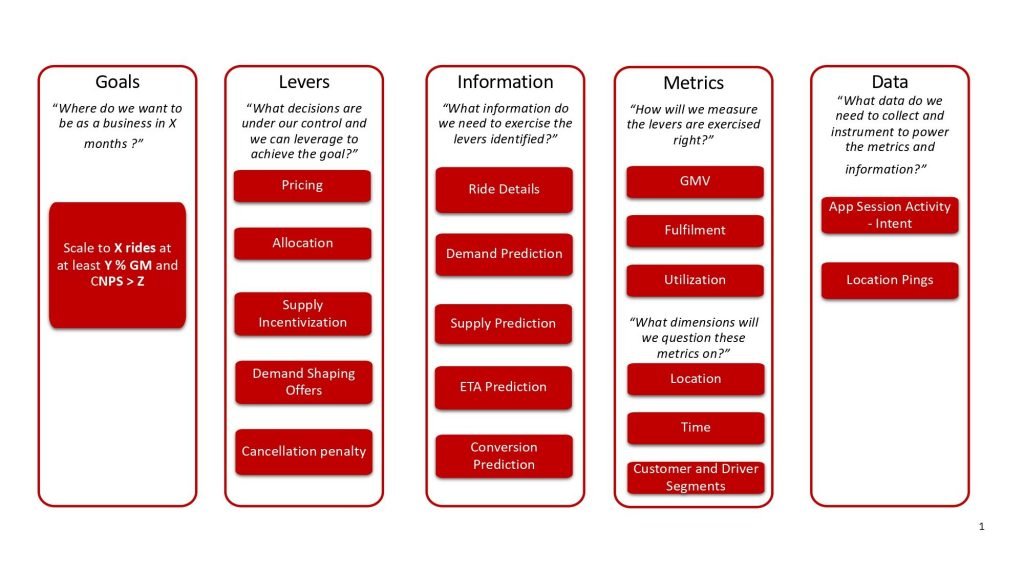
Goal
The starting point for data strategy is the business goal. As an example for ride hailing, it would look like – Scale to X million rides with at least Y% Gross Margin maintaining customer NPS above Z. Like every business goal, there is an objective and a few guardrails.
Lever
The next step is to ask the question “what are the levers?”. Levers are basically decisions under our control to achieve the goal. There are several levers like pricing, allocation and supply incentivization that exist in a ride hailing context
Often levers are confused with metrics. Usually people define a lever like –“improve conversion on website”. Conversion is just a metric.. What drives that conversion like the keywords used or button placement are the levers.
Information
The next question is what information would help exercise the levers in the best way possible? Information could be in the form of raw data, processed data or a prediction that can help either a human being or a system make a decision. For example, pricing as a lever would use information on predicted demand, predicted supply and customer conversion behavior to decide on the price. All data science model predictions would eventually be powering some decisions for business.
Metric
The most important question to ask next is how do we know the decision made is right? Is there a metric that can measure the effectiveness of a lever in an isolated manner? Is there a metric that moves along with the effectiveness of the lever?
Many would argue conversion is a metric for pricing. Yes and No. Conversion is a metric only when pricing is optimizing for growth. When optimizing for profitability or revenue, we would intentionally reduce conversion under high demand scenarios. In such a case, conversion is not the right metric that moves with the effectiveness of the lever.
The special case with metrics is that there is an adjoining question to ask. What are the questions that we would ask when this metric shows unusual behavior? For example, if the revenue is not looking right, some of the immediate questions would be – Which cities? Which customer segments? Which days?. These questions provide us the dimensions to add to this metric on the business intelligence dashboards.
A little bit of upfront thought can save many painful time-taking cycles of reactive discovery and addition of dimensions to dashboards.
Data
Finally, the last question to ask is what raw data should be collected to power the information and metrics ? This is the step that opens up gaps in data strategy. For example, demand prediction would never have complete data if the UI of a ride hailing app only collected destination of riders who got a cab. Collecting the destination intent of every user before requesting for a ride as the default flow adds rich data for demand prediction. Such upfront thought in data strategy saves a lot of erroneous assumptions and approximations in the future.
If we glance through the drive train model, it does not need the business to be up and operating for years. Rather, soon after product market fit is the right stage to do this exercise and realize the gaps!!
2. We have collected a lot of data… and made it usable and accessible via data platform
When startups say we have collected a lot of data, yes surely they have. But the data collected from different sources would still be siloed without talking to each other. A lot of data, especially those of sales and finance is often entered manually into google sheets. There would be a lot of people internally waiting to access this data and track metrics, analyse to gain insights and model to make decisions. But the bridge of a data platform that connects these various data generators to end users is missing.
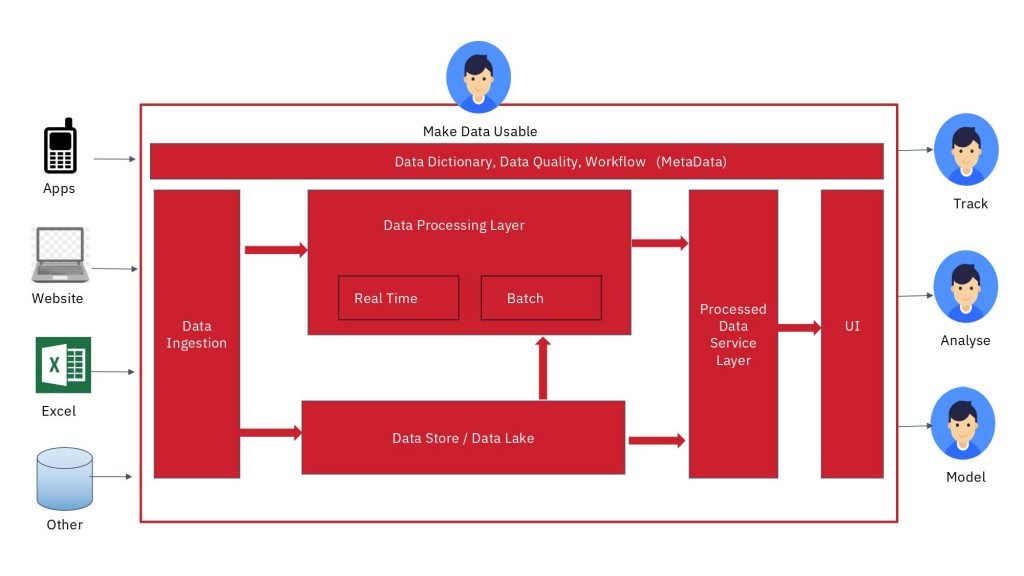
A startup can confidently make the statement that they have collected a lot of data only when they go beyond just data ingestion and build the basic blocks of a data platform.
- Data lake – a raw data store where all the data from different data generating systems can flow
- Processing Layer –real time and automated batch processing that converts raw data into easily consumable information
- Data Warehouse –storage of processed data with well designed schema for accessing key metrics and conducting analysis
- Querying Layer –for analysts and data scientists to query the data in the data warehouse
- Visualization Layer –dashboards to visualize key metrics and drill down into dimensions
- Data dictionary, meta data and data quality reporting – dictionary of data availability to make data discoverable along with report on quality of the data for trust
The data platform becomes a reality when there is an owner within the startup for making data discoverable, trustworthy, usable and accessible.
3. We need to hire data scientists – not yet, wait
For a startup to reap the benefit of hiring data scientists, there are four questions that need to be asked first:
- Have we hired a team of data engineers that make data usable and accessible?
- Have we tasted the benefit of data through a team of analysts who help with one-time decisions, root cause analysis and opportunity sizing for strategic initiatives leveraging data?
- Are there repeated decisions that systems need to make automatically that data scientists can drive?
- Do we have a plan to hire ML engineers who can deploy models to production and maintain?
Answering these questions not only helps assess readiness but also creates clarity of the different roles required during the data science journey.
The most confused roles are often analysts vs. data scientists. The best way to differentiate is one-time decisions vs repeated decisions. Analysts support a lot of strategic and tactical one-time decisions and root cause analysis with facts and insights. Data scientists support models that enable automated decision making by systems.
4. What problems can data scientists solve given the data we have collected?
The beauty of the drivetrain model is that the information block automatically creates a prioritized work plan for data scientists that totally removes the condition of “given the data we have collected” from this question. The models in the information block are connected to all the levers that they could drive as well as to the data elements that power them. The models that drive the most number of levers and have data readiness are the ones that would automatically get prioritized as the fundamental models data scientists need to build.
It is not surprising to see that fundamental models are often missing even in companies that are no longer startups. This is only because every time the work done by data scientists is usually driven by a specific use case that needs to be implemented ASAP and fundamental core models that are inputs to these are built in quick fix mode.
5. Did Will it have measurable impact?
When it comes to impact, the question should not be asked in hindsight, but the implementation has to be clearly set up for success at the outset. The three fundamental questions to ask and answer well before the start of implementation of an idea are:
What is the isolable metric? If not isolable, what are the interacting levers to have control over?
An isolable metric is not an easy one to find always. Hence maintaining a degree of control over all ongoing experiments which are a significant number in a startup context becomes key. An A/B platform with a dashboard of all ongoing experiments will do the trick.
What is the right cut for A/B that can ensure least interference?
Any experiment that goes beyond a single customer interacting with “a version” of a webpage can never ignore interference between control and test. For example, while experimenting on supply positioning in a mobility scenario, there is no cut of A/B among customers, vehicles or geographical boundaries that minimizes interference. The only cut possible is different time frames for control and test.
Do we need attribution models that link organic factors to the metric under control conditions?
The moment control and test are separated in time, dynamic nature of organic factors like demand and supply hinder direct comparison of metrics. Attribution models that build a relationship between organic factors and metrics become key to measure impact during such situations.
All the aspects of measuring impact, whether it is an A/B platform or design of experiment or attribution models cannot be achieved overnight without upfront thought process on measurement of impact.
Recap
If we have to recap, how typical data science journey of a startup could be changed to ideal here are the modified stages of the journey.
- We are collecting all the data we should
- We have collected a lot of data and made it usable and accessible via data platform
- We need to hire data engineers, analysts before data scientists and ml engineers
- We have identified the high leverage data ready problems for business impact that data scientists will focus on
- We have identified the metric and design of experiment to measure the impact
If so, there will be impact and why not!





Very insightful article, the drive train model can also be used by established firms to improve their analytics capability and performance focus.